
판다스는 무엇이고 왜 사용하는가?
우리는 지금 파이썬을 이용해서 데이터를 다루고 처리하는 것을 공부하고 있다.
이 때까지 파이썬은 많은 데이터를 가지고 연산하고 가공하는 데에
우수한 능력을 보여주었다.
그런데 엑셀 파일과 같이 테이블 형태의 데이터에 대한 통계적 분석이나
데이터 항목 사이의 연산 등에는 적합하지 않았다.
이 때 "판다스 Pandas" 를 이용한다.
판다스는 넘파이를 기반으로 한 도구이고 다음과 같은 특징을 갖는다.
- 빠르고 효율적이며 다양한 표현력을 갖춘 자료구조
- 다양한 형태의 데이터에 적합
- 핵심 구조 : Series, DataFrame
우리는 판다스로 무엇을 할 수 있을까?
판다스를 이용하면 CSV파일, 엑셀파일, SQL 데이터베이스에서 데이터를 읽어서
스프레드시트의 테이블과 유사한 데이터프레임이라는 파이썬 객체로 만들 수 있다.
일단 데이터들이 데이터프레임 객체로 만들어지면 파이썬의 for loop 를 통해 작업하는 것보다
훨씬 쉽게 데이터 항목들에 접근하고 처리할 수 있다.
우선 판다스를 알기 이전에 CSV 라는 파일 형식에 대해 간단하게 알고 넘어가자.
CSV ( : Comma Separated Variable ) 는 구조화된 텍스트 파일 형식이다.
기본적으로 쉼표를 이용하여 데이터를 구분한다.
물론 쉼표가 아닌 어떤 구분자라도 사용이 가능하다.
즉, 탭이나 콜론, 세미콜론 등의 구분자를 사용해 구조화시켜놓은 텍스트 파일을 의미한다.
CSV 는 Excel 과 같은 스프레드 시트 소프트웨어에 적합한 형식이다.
데이터 과학에서 사용되는 데이터 가운데 상당한 비율의 데이터들이 CSV 형식으로 공유되는 경우가 많다.
CSV 파일은 필드를 나타내는 열과 레코드를 나타내는 행으로 구성된다.
그럼 이제, CSV 로 저장된 데이터를 사용해보자.
파이썬 모듈 csv 는 CSV reader 와 CSV writer 를 제공한다.
예시로 사용할 CSV 파일이 필요한데, 기상자료개방 포털 사이트에 들어가면 지난 기상자료를
다운로드할 수 있는 API 를 제공한다.
미리 2011년 8월 1일부터 2020년 8월 1일까지 9년 동안의 울릉도의 기온과 풍속 데이터를 받아
github 에 올려두었으니, 예시로 사용하고 싶으면 다운로드해서 사용하면 되겠다.
https://github.com/casperWebmon/DataScience/blob/main/weather.csv
casperWebmon/DataScience
Contribute to casperWebmon/DataScience development by creating an account on GitHub.
github.com
이 파일을 c: 드라이브의 data 폴더에 'weather.csv' 로 저장했다고 가정하고, 다음과 같이 수행해보자.
import csv
f = open('c:/data/weather.csv') # CSV 파일을 열어서 f에 저장한다.
data = csv.reader(f) # reader() 함수를 이용하여 읽는다.
for row in data:
print(row)
f.close()
경로를 틀리지 않고 이 코드를 실행했다면, 다음과 같은 결과화면이 나올 것이다.
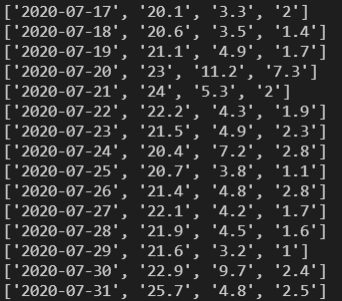
데이터가 많기 때문에 출력 결과의 일부분만 캡쳐했다.
CSV 파일에 저장된 데이터를 한 줄씩 읽으려면 반복문을 사용해야 한다.
CSV 파일의 각 행의 데이터가 리스트에 저장되어서 우리에게 전달된다.
실행결과가 많이 나오지만, 실행결과의 첫 번째 라인을 살펴보자.

다음과 같이 첫 번째 행은 데이터의 속성을 표시하는 일시, 평균기온, 최대풍속 등의 헤더이다.
만약 헤더를 제거하고 나머지 데이터만을 읽으려면 어떻게 해야 할까?
다음과 같이 next() 함수를 이용하면 된다.
import csv
f = open('c:/data/weather.csv') # CSV 파일을 열어서 f에 저장한다.
data = csv.reader(f) # reader() 함수를 이용하여 읽는다.
header = next(data) # 헤더를 제거한다.
for row in data: # 반복 루프를 사용하여 데이터를 읽는다.
print(row)
f.close() # 파일을 닫는다.
그럼 이제 단순히 데이터를 읽어오는 것이 아니라 데이터를 이용해서 원하는 열을 뽑아내보자.
울릉도에서 몇 월에 가장 바람이 강한 지 분석해보자.
앞서 사용했던 울릉도의 기상 데이터에는 일일 평균 풍속 데이터가 있다.
이 데이터를 바탕으로 몇 월의 울릉도가 가장 바람이 강한지 알아보고 싶다.
결과는 아래와 같다. 달이 0부터 시작하여 11까지 있고,
3일 때에 가장 큰 풍속을 보이므로, 울릉도는 4월에 가장 강한 바람이 분다는 것을 알 수 있다.

그러면 해답 코드를 보면서 어떻게 짜면 되는지 알아보자.
import csv
import matplotlib.pyplot as plt
f = open('c:/data/weather.csv') # CSV 파일 열어 f에 저장
data = csv.reader(f) # reader() 함수로 읽기
header = next(data) # 헤더를 제거
monthly_wind = [ 0 for x in range(12) ] # 매달 풍속을 담을 리스트
days_counted = [ 0 for x in range(12) ] # 각 달마다 측정된 일수
for row in data:
month = int(row[0][5:7]) # 0번 열에서 달 정보 추출
if row[3] != '' : # 풍속 데이터 존재하는지 확인
wind = float(row[3]) # 풍속을 얻어 온다.
monthly_wind[month-1] += wind # 해당 달에 풍속 데이터 추가
days_counted[month-1] += 1 # 해당 달의 일수를 증가
for i in range(12) :
monthly_wind[i] /= days_counted[i] # 일수로 나누어 월평균 구하기
plt.plot(monthly_wind, 'blue')
plt.show()
f.close() # 파일을 닫는다.
각 달의 평균 풍속을 구하기 위한 12개 항목을 가진 리스트 mothly_wind 를 만든다.
각 달마다 측정 데이터가 존재하는 일수를 담을 12개 항목의 리스트 days_counted 도 함께 만든다.
각 행 데이터를 읽어 해당 데이터가 몇 월의 데이터인지 확인하고, 풍속 정보가 있는지 확인한다.
여기서 첫 열에 있는 '2012-01-24' 와 같은 문자열의 [5:7] 을 읽으면 달의 정보가 된다.
풍속이 존재하면 해당 월의 풍속 정보에 이 데이터를 더하고, 고려된 일수 days_counted 도
해당 월 정보를 증가시킨다.
마지막으로 누적된 풍속 데이터를 계산된 일수로 나누어 월 평균 풍속을 구한다.
CSV 파일과 같은 데이터는 필드와 레코드를 어떻게 뜯어낼 지에 대해서 고민하면
크게 어렵지 않게 데이터를 추출해 낼 수 있다.
이제 판다스의 데이터 구조인 시리즈와 데이터프레임에 대해 간단히 알아보자.
위에서 우리가 사용했던 csv 모듈 말고도 CSV 데이터를 처리할 수 있는 모듈이 있다.
이들 중 가장 강력한 모듈이 판다스인데,
판다스는 데이터 저장을 위하여 2가지의 데이터 구조를 제공하고 있다.
| 데이터 구조 | 차원 | 설명 |
| 시리즈 | 1 | 레이블이 붙어있는 1차원 벡터 |
| 데이터프레임 | 2 | 행과 열로 되어있는 2차원 테이블, 각 열은 시리즈로 되어 있다. |
이들 데이터 구조는 모두 넘파이 배열을 이용하여 구현되어서 속도가 빠르다.
각 행과 열은 이름이 부여되는데, 행의 이름을 "index", 열의 이름을 "columns" 라 부른다.
판다스의 시리즈 데이터를 만드는 것은 Series 클래스를 이용한다.
이 클래스를 생성할 때 리스트를 넘겨주면 이 리스트를 이용하여 1차원 벡터 구조의 시리즈 데이터를 생성한다.
import numpy as np
import pandas as pd
series = pd.Series([1, 3, 4, np.nan, 6, 8])
print(series)
여기서 nan 은 Not a number 의 약어로 넘파이에서 수치 연산은 가능하지만 정의할 수 없는 값을 의미한다.
위 코드의 실행 결과를 보자.
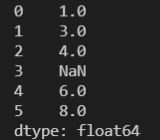
1차원 벡터를 생성한 것을 확인할 수 있다.
이번에는 데이터프레임에 대해 알아보자.
데이터프레임은 시리즈 데이터가 여러 개 모여서 2차원 구조를 가지는 것을 의미한다.
이 데이터프레임은 판다스가 데이터를 분석할 때 사용하는 기본적 틀이다.
하나의 데이터프레임은 행과 열로 구분할 수 있는데, 하나의 행은 여러 종류의 데이터를 담고 있다.
모든 행은 동일한 형태의 자료 배치를 가진다.
아래 예에서 모든 행은 [이름, 나이, 성별]의 데이터를 가진다.
그리고 각 열은 동일한 자료형을 가진 시리즈 임을 알 수 있다.
| 이름 | 나이 | 성별 |
| 이주원 | 24 | 남 |
| 김짱구 | 22 | 남 |
| 김짱아 | 20 | 여 |
이제 각각의 시리즤들을 모아 데이터 프레임을 만들어 보자.
import numpy as np
import pandas as pd
name = pd.Series(['이주원', '김짱구', '김짱아']) # 이름에 해당하는 시리즈 생성.
age = pd.Series([24, 22, 20]) # 나이에 해당하는 시리즈 생성.
sex = pd.Series(['남', '남', '여']) # 성별에 해당하는 시리즈 생성.
df = pd.DataFrame({'이름' : name, '나이' : age, '성별' : sex})
# 시리즈들을 모아 데이터프레임 생성.
print(df)
데이터프레임을 만들 때는 판다스의 DataFrame 클래스를 사용한다.
데이터프레임을 생성하기 위한 인자로 시리즈들을 나열하면 되는데, 딕셔너리 구조로 입력한다.
딕셔너리의 key 는 시리즈가 차지할 column 의 이름, value 는 시리즈가 된다.
위 코드의 실행 결과는 다음과 같다.

하지만 보통 데이터 분석을 할 때는 데이터프레임을 직접 생성하지 않고,
판다스를 이용하여 데이터 파일을 읽어서 데이터프레임 형태로 데이터를 저장한 후 분석한다.
이제 우리는 데이터프레임 형태를 이용해 저장한 데이터를 넘파이 연산을 이용해 빠르게 다룰 수 있고,
앞서 배웠던 matplotlib 을 이용해 차트로 나타낼 수 있다.
이번 장에서 판다스를 통해 드디어 외부의 파일을 불러와서 데이터를 다뤄 볼 수 있어서 기뻤다.
더 다양한 데이터를 다루어보고, 내 입맛대로 데이터를 분석해보는 시간을 가지면 좋겠다 :)
출처 : 따라하며 배우는 파이썬과 데이터 과학 - 천인국, 박동규, 강영민