
이동욱님의 스프링 부트와 AWS 로 혼자 구현하는 웹 서비스 와
인프런 김영한님의 자바 ORM 표준 JPA 프로그래밍 기본편 을 보다가
JPA 에 대해 이해하기 쉽게 설명된 부분이 있어 인용해서 적어보았다.
웹 서비스를 개발하면서 피할 수 없는 문제는 DB 를 다루는 일이다.
특히 백엔드 개발자를 희망하고 공부하면서 느끼는 점은
DB를 다룰 일이 생각보다 많다는 것.
당장 백엔드 프레임워크를 이용해서 어플리케이션 개발에 몰두하기에도 시간이 부족한데,
DB는 또 언제 공부하는지..
어쨌든 RDB 를 이용하는 프로젝트에서 어떻게 객체지향 프로그래밍을 할 수 있을까 에 대한 해답으로
JPA 라는 자바 표준 ORM (Object Relational Mapping) 기술을 만나게 된다.
참고로 MyBatis, iBatis 는 ORM 이 아니라 SQL Mapper 이다.
ORM 은 객체를 Mapping 하는 것이고, SQL Mapper 는 쿼리를 매핑한다 !
우선 RDB 에서 각 테이블마다 기본적인 CRUD SQL 생성은 피할 수 없다.
CRUD : Create, Read, Update, Delete
아무리 Java 클래스를 잘 설계해도, 결국 SQL 을 통해야 DB 에 저장하고 조회할 수 있다.
이 반복적인 작업을 해야 한다는 것이 첫 번째 문제.
개발자가 거의 SQL 매퍼의 일을 하고 있는 것이다.
또 하나는 패러다임 불일치 문제이다.
RDB 는 어떻게 데이터를 저장할지에 초점이 맞춰진 기술이다.
반대로 객체지향 프로그래밍은 기능과 속성을 한 곳에 관리하는 기술이다.
이 둘은 이미 사상부터 다른 시작점에서 출발했다.
RDB 와 객체지향 프로그래밍 언어의 패러다임이 서로 다른데,
객체를 DB에 저장하려고 하니 여러 문제가 발생하고 이를 패러다임 불일치라고 한다.
그렇다면 객체와 RDB 의 차이를 살펴보자.
- 상속
객체에는 상속관계가 있고, RDB에는 상속관계가 없다고 볼 수 있다.
(유사한 게 있지만)

Album 에 insert 할 때는 객체를 분해한 다음에 insert 를 두 번 해야한다.
조회할 때는 ITEM 과 ALBUM 을 join 쿼리를 만든 후 가져와야 한다.
Java Collection 에 저장한다면 ?
아래와 같이 단순해진다.
Album album = list.get(albumId);
// 부모 타입으로 조회 후 다형성 활용
Item item = list.get(albumId);
예를 들어, 객체지향 프로그래밍에서 부모가 되는 객체를 가져오려면 어떻게 해야 할까?
User user = findUser();
Group group = user.getGroup();
누구나 명확하게 User 와 Group 은 부모-자식 관계임을 알 수 있다.
하지만 여기에 DB 가 추가된다면 ?
User user = userDao.findUser();
Group group = groupDao.findGroup(user.getGroupId());
User 따로, Group 따로 조회하게 된다.
상속이나 1:N 등 다양한 객체 모델링을 DB로는 구현할 수 없다.
- 연관관계
객체는 참조를 사용하고,
테이블은 외래 키를 사용한다 →JOIN ON M.TEAM_ID = T.TEAM_ID
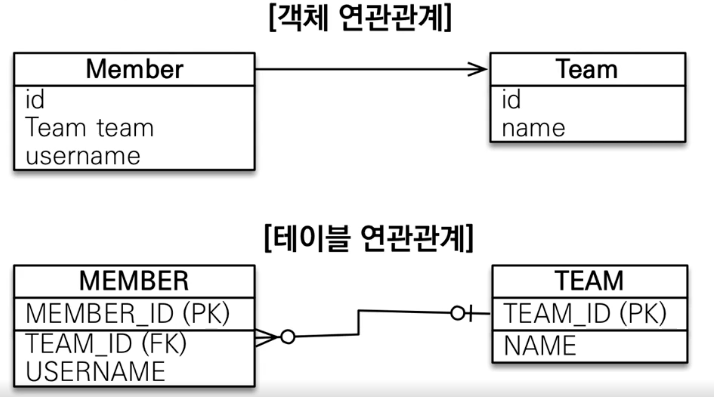
객체는 Team 에서 Member 로 갈 수 없다. (참조가 없기 때문에)
MEMBER 의 TEAM_ID (FK) 를 join 해서 가져올 수 있다.

위와 같은 여러 연관관계를 가지고 있다고 가정했을 때,
엔티티 신뢰 문제 가 발생한다.
SELECT M.*, T.*
FROM MEMBER M
JOIN TEAM T ON M.TEAM_ID = T.TEAM_ID
다음 SQL 을 실행하고 나서 객체에 매핑했다고 하자.
Member 객체에서 team 과 order 정보를 가져오려고 하면 어떻게 될까?
member.getTeam(); //OK
member.getOrder(); //null
처음 실행하는 SQL 에 따라서 탐색 범위가 결정되어 버린다.
Member 와 Team 만 값을 채워 가져왔고, Order 정보는 가져오지 않았다.
이는 결국 엔티티 신뢰 문제 로 이어진다 ‼️
class MemberService {
...
public void process() {
Member member = memberDAO.find(memberId);
member.getTeam(); //???
member.getOrder.getDelivery(); //???
}
}
위 코드에서 memberDAO 에서 어떤 쿼리가 날아갔고
어떤 데이터를 담아 조립했는지 눈으로 확인하지 않는 이상
Member 와 연관관계에 있는 Team 과 Order 정보를 신뢰하고 사용할 수 없다 !
Layered Architecture 는 다음 계층에서 신뢰하고 쓸 수 있어야 하는데
엔티티를 신뢰하고 쓸 수 없다는 큰 문제점이 발생한다.
그렇다고 모든 객체를 미리 로딩할 수는 없다 ..
그럼 어떤 대안이 있을까 ?
상황에 따라 동일한 조회 메소드를 여러 개 생성해두어야 한다.
memberDAO.getMember(); // Member 만 조회
memberDAO.getMemberWithTeam(); // Member 와 Team 조회
memberDAO.getMemberWithOrderWithDelivery(); // Member,Order,Delivery 조회
...이렇게 하나하나 만들어두면, 계층형 아키텍처에서 진정한 의미의 계층 분할 이 어렵다.
이번엔 쿼리로 조회했을 때와 Java Collection 에서 조회했을 때를 비교해보자.
쿼리로 조회했을 때 ⬇️
String memberId = "100";
Member member1 = memberDAO.getMember(memberId);
Member member2 = memberDAO.getMember(memberId);
member1 == member2 // 다르다 !
class MemberDAO {
public Member getMember(String memberId) {
String sql = "SELECT * FROM MEMBER WHERE MEMBER_ID = ?";
...
//JDBC API, SQL 실행
return new Member(...);
}
}
Java Collection 에서 조회했을 때 ⬇️
String memberId = "100";
Member member1 = list.get(memberId);
Member member2 = list.get(memberId);
member1 == member2 // 같다 !
결론을 지어보면, 객체답게 모델링 할수록 매핑 작업만 늘어나게 된다.
“객체를 Java Collection 에 저장하듯이 RDB 에 저장할 수는 없을까?”
에 대한 고민의 결과가 바로 JPA (Java Persistence API) 이다 !
JPA 는 이런 문제점을 해결하기 위해 등장하게 되었고,
서로 지향하는 바가 다른 2개 영역을 중간에서 패러다임 일치를 시켜준다.
JPA 는 인터페이스로, 자바 표준명세서이다.
인터페이스인 JPA 를 사용하기 위해서는 구현체가 필요한데,
대표적으로 Hibernate, Eclipse Link 등이 있다.
하지만 Spring 에서 JPA 를 사용할 때는 이 구현체들을 직접 다루진 않고,
좀 더 쉽게 사용하고자 추상화시킨 Spring Data JPA 라는 모듈을 이용해 JPA 를 다룬다.
이들의 관계는 다음과 같다.
- JPA ← Hibernate ← Spring Data JPA
Hibernate 를 쓰는 것과 Spring Data JPA 를 쓰는 것 사이에는 큰 차이가 없지만
Spring 에서는 Spring Data JPA 를 쓰는 것을 권장하는데,
그 이유는 크게 두 가지가 있다.
- 구현체 교체의 용이성
- 저장소 교체의 용이성
먼저 구현체 교체의 용이성이란 Hibernate 외에 다른 구현체로 쉽게 교체하기 위함이다.
Spring Data JPA 는 내부에서 구현체 Mapping 을 지원해주기 때문에
다른 JPA 구현체를 사용할 때 아주 쉽게 교체할 수 있다.
다음으로 저장소 교체의 용이성이란 RDB 외에 다른 저장소로 쉽게 교체하기 위함이다.
예를 들어, 트래픽이 많아져 RDB 로는 감당이 안 될때
MongoDB 로 교체가 필요하다면 Spring Data JPA 에서 Spring Data MongoDB 로
의존성만 교체하면 된다.
이는 Spring Data 의 하위 프로젝트들은 기본적인 CRUD 의 인터페이스가 같기 때문이다.
예를 들어 save(), findAll, findOne() 등을 인터페이스로 가지고 있다.
이 때문에 저장소가 교체되어도 기본적인 기능은 바뀔 것이 없다.
이런 장점들로 인해 Spring 측에서는 Spring Data 프로젝트를 권장한다.
JPA 를 잘 사용하려면 객체지향 프로그래밍과 RDB, 두 가지 모두 잘 이해하고 있어야 한다.
결국 열심히 공부하고 사용해보아야 한다는 뜻이다 🙂
급결론 : 아직 배울 게 많다.